

Neo core API Reference#
Relationships between Neo objects#
- Object:
With a star = inherits from
Quantity
- Attributes:
In red = required
In white = recommended
- Relationships:
In cyan = one to many
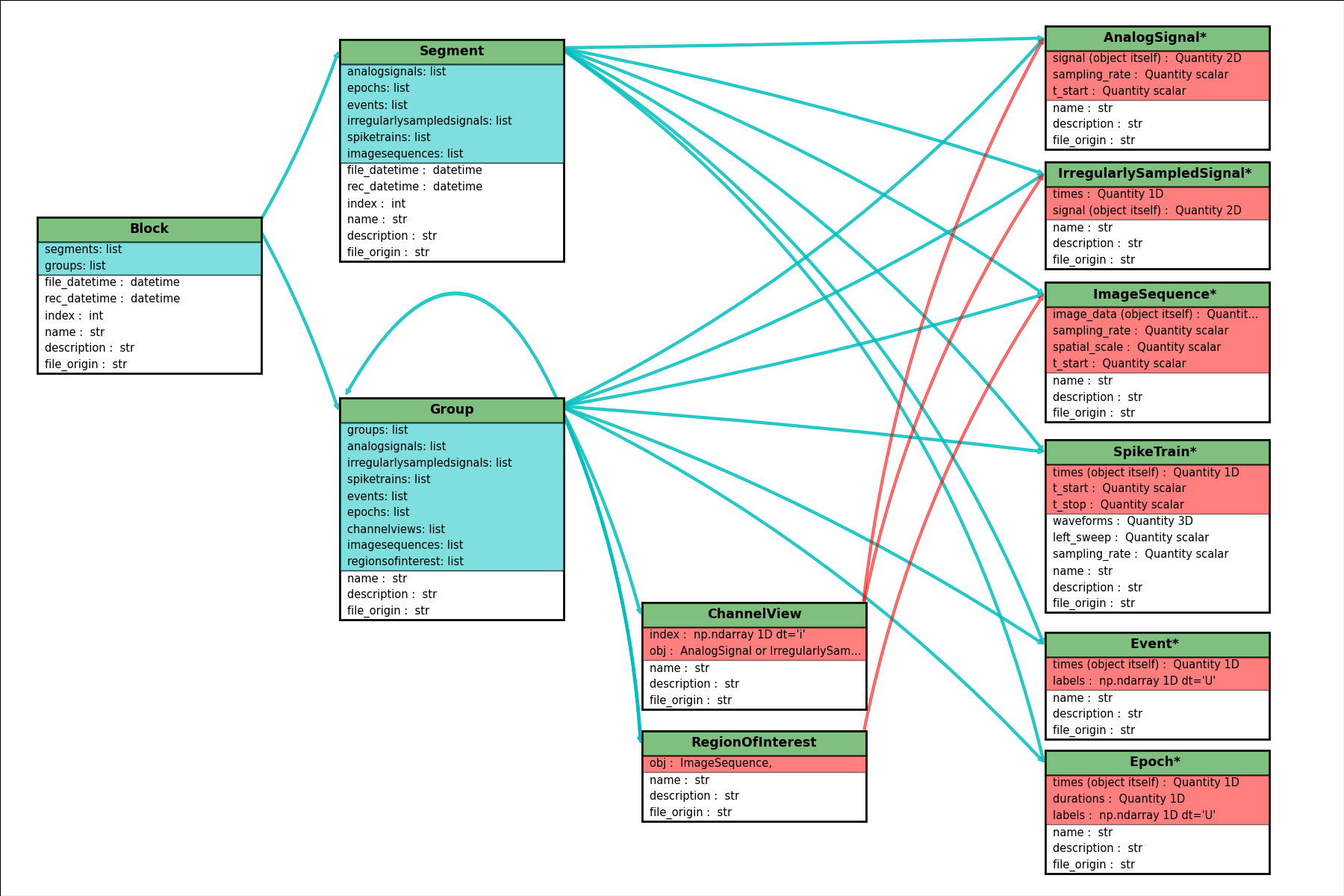
Click here for a better quality SVG diagram
{kind=link}
Note
This figure does not include ChannelView and RegionOfInterest.
neo.core provides classes for storing common electrophysiological data
types. Some of these classes contain raw data, such as spike trains or
analog signals, while others are containers to organize other classes
(including both data classes and other container classes).
Classes from neo.io return nested data structures containing one
or more classes from this module.
Classes:
- class neo.core.Block(name=None, description=None, file_origin=None, file_datetime=None, rec_datetime=None, index=None, **annotations)#
Main container gathering all the data, whether discrete or continuous, for a given recording session.
A block is not necessarily temporally homogeneous, in contrast to
Segment.Usage:
>>> from neo.core import Block, Segment, Group, AnalogSignal >>> from quantities import nA, kHz >>> import numpy as np >>> >>> # create a Block with 3 Segment and 2 Group objects ,,, blk = Block() >>> for ind in range(3): ... seg = Segment(name='segment %d' % ind, index=ind) ... blk.segments.append(seg) ... >>> for ind in range(2): ... group = Group(name='Array probe %d' % ind) ... blk.groups.append(group) ... >>> # Populate the Block with AnalogSignal objects ... for seg in blk.segments: ... for group in blk.groups: ... a = AnalogSignal(np.random.randn(10000, 64)*nA, ... sampling_rate=10*kHz) ... group.analogsignals.append(a) ... seg.analogsignals.append(a)
- Required attributes/properties:
None
- Recommended attributes/properties:
- name:
(str) A label for the dataset.
- description:
(str) Text description.
- file_origin:
(str) Filesystem path or URL of the original data file.
- file_datetime:
(datetime) The creation date and time of the original data file.
- rec_datetime:
(datetime) The date and time of the original recording.
Note: Any other additional arguments are assumed to be user-specific metadata and stored in
annotations.
- Block.filter(targdict=None, data=True, container=False, recursive=True, objects=None, **kwargs)#
Return a list of child objects matching any of the search terms in either their attributes or annotations. Search terms can be provided as keyword arguments or a dictionary, either as a positional argument after data or to the argument targdict. A key of a provided dictionary is the name of the requested annotation and the value is a FilterCondition object. E.g.: equal(x), less_than(x), InRange(x, y).
targdict can also be a list of dictionaries, in which case the filters are applied sequentially.
A list of dictionaries is handled as follows: [ { or } and { or } ] If targdict and kwargs are both supplied, the targdict filters are applied first, followed by the kwarg filters. A targdict of None or {} corresponds to no filters applied, therefore returning all child objects. Default targdict is None.
If data is True (default), include data objects. If container is True (default False), include container objects. If recursive is True (default), descend into child containers for objects.
objects (optional) should be the name of a Neo object type, a neo object class, or a list of one or both of these. If specified, only these objects will be returned. If not specified any type of object is returned. Default is None. Note that if recursive is True, containers not in objects will still be descended into. This overrides data and container.
Examples:
>>> obj.filter(name="Vm") >>> obj.filter(objects=neo.SpikeTrain) >>> obj.filter(targdict={'myannotation':3}) >>> obj.filter(name=neo.core.filters.Equal(5)) >>> obj.filter({'name': neo.core.filters.LessThan(5)})
- class neo.core.Segment(name=None, description=None, file_origin=None, file_datetime=None, rec_datetime=None, index=None, **annotations)#
A container for data sharing a common time basis.
A
Segmentis a heterogeneous container for discrete or continuous data sharing a common clock (time basis) but not necessary the same sampling rate, start or end time.Parameters#
- name: str | None, default: None
A label for the dataset.
- description: str | None, default: None
Text description.
- file_origin: str | None, default: None
Filesystem path or URL of the original data file.
- rec_datetime: datetime.datetime| None, default: None
The date and time of the original recording
- index: int | None, default: None
You can use this to define a temporal ordering of your Segment. For instance you could use this for trial numbers.
- annotations: dict | None,
Other keyword annotations for the dataset
Examples#
>>> from neo.core import Segment, SpikeTrain, AnalogSignal >>> from quantities import Hz, s >>> >>> seg = Segment(index=5) >>> >>> train0 = SpikeTrain(times=[.01, 3.3, 9.3], units='sec', t_stop=10) >>> seg.spiketrains.append(train0) >>> >>> train1 = SpikeTrain(times=[100.01, 103.3, 109.3], units='sec', ... t_stop=110) >>> seg.spiketrains.append(train1) >>> >>> sig0 = AnalogSignal(signal=[.01, 3.3, 9.3], units='uV', ... sampling_rate=1*Hz) >>> seg.analogsignals.append(sig0) >>> >>> sig1 = AnalogSignal(signal=[100.01, 103.3, 109.3], units='nA', ... sampling_period=.1*s) >>> seg.analogsignals.append(sig1)
Notes#
- Container of:
EpochEventAnalogSignalIrregularlySampledSignalSpikeTrain
- Segment.filter(targdict=None, data=True, container=False, recursive=True, objects=None, **kwargs)#
Return a list of child objects matching any of the search terms in either their attributes or annotations. Search terms can be provided as keyword arguments or a dictionary, either as a positional argument after data or to the argument targdict. A key of a provided dictionary is the name of the requested annotation and the value is a FilterCondition object. E.g.: equal(x), less_than(x), InRange(x, y).
targdict can also be a list of dictionaries, in which case the filters are applied sequentially.
A list of dictionaries is handled as follows: [ { or } and { or } ] If targdict and kwargs are both supplied, the targdict filters are applied first, followed by the kwarg filters. A targdict of None or {} corresponds to no filters applied, therefore returning all child objects. Default targdict is None.
If data is True (default), include data objects. If container is True (default False), include container objects. If recursive is True (default), descend into child containers for objects.
objects (optional) should be the name of a Neo object type, a neo object class, or a list of one or both of these. If specified, only these objects will be returned. If not specified any type of object is returned. Default is None. Note that if recursive is True, containers not in objects will still be descended into. This overrides data and container.
Examples:
>>> obj.filter(name="Vm") >>> obj.filter(objects=neo.SpikeTrain) >>> obj.filter(targdict={'myannotation':3}) >>> obj.filter(name=neo.core.filters.Equal(5)) >>> obj.filter({'name': neo.core.filters.LessThan(5)})
- class neo.core.Group(objects=None, name=None, description=None, file_origin=None, allowed_types=None, **annotations)#
Can contain any of the data objects, views, or other groups, outside the hierarchy of the segment and block containers. A common use is to link the
SpikeTrainobjects within aBlock, possibly across multiple Segments, that were emitted by the same neuron.- Required attributes/properties:
None
- Recommended attributes/properties:
- objects:
(Neo object) Objects with which to pre-populate the
Group- name:
(str) A label for the group.
- description:
(str) Text description.
- file_origin:
(str) Filesystem path or URL of the original data file.
- Optional arguments:
- allowed_types:
(list or tuple) Types of Neo object that are allowed to be added to the Group. If not specified, any Neo object can be added.
- Note: Any other additional arguments are assumed to be user-specific
metadata and stored in
annotations.- Container of:
AnalogSignal,IrregularlySampledSignal,SpikeTrain,Event,Epoch,ChannelView,Group
- class neo.core.AnalogSignal(signal, units=None, dtype=None, copy=None, t_start=array(0.) * s, sampling_rate=None, sampling_period=None, name=None, file_origin=None, description=None, array_annotations=None, **annotations)#
Array of one or more continuous analog signals.
A representation of several continuous, analog signals that have the same duration, sampling rate and start time. Basically, it is a 2D array: dim 0 is time, dim 1 is channel index
Inherits from
quantities.Quantity, which in turn inherits fromnumpy.ndarray.Usage:
>>> from neo.core import AnalogSignal >>> import quantities as pq >>> >>> sigarr = AnalogSignal([[1, 2, 3], [4, 5, 6]], units='V', ... sampling_rate=1*pq.Hz) >>> >>> sigarr <AnalogSignal(array([[1, 2, 3], [4, 5, 6]]) * mV, [0.0 s, 2.0 s], sampling rate: 1.0 Hz)> >>> sigarr[:,1] <AnalogSignal(array([2, 5]) * V, [0.0 s, 2.0 s], sampling rate: 1.0 Hz)> >>> sigarr[1, 1] array(5) * V
- Required attributes/properties:
- signal:
(quantity array 2D, numpy array 2D, or list (data, channel)) The data itself.
- units:
(quantity units) Required if the signal is a list or NumPy array, not if it is a
Quantity- t_start:
(quantity scalar) Time when signal begins
- sampling_rate:
or sampling_period (quantity scalar) Number of samples per unit time or interval between two samples. If both are specified, they are checked for consistency.
- Recommended attributes/properties:
- name:
(str) A label for the dataset.
- description:
(str) Text description.
- file_origin:
(str) Filesystem path or URL of the original data file.
- Optional attributes/properties:
- dtype:
(numpy dtype or str) Override the dtype of the signal array.
- copy:
(bool) True by default.
- array_annotations:
(dict) Dict mapping strings to numpy arrays containing annotations for all data points
Note: Any other additional arguments are assumed to be user-specific metadata and stored in
annotations.- Properties available on this object:
- sampling_rate:
(quantity scalar) Number of samples per unit time. (1/
sampling_period)- sampling_period:
(quantity scalar) Interval between two samples. (1/
quantity scalar)- duration:
(Quantity) Signal duration, read-only. (size *
sampling_period)- t_stop:
(quantity scalar) Time when signal ends, read-only. (
t_start+duration)- times:
(quantity 1D) The time points of each sample of the signal, read-only. (
t_start+ arange(shape`[0])/:attr:`sampling_rate)
- Slicing:
AnalogSignalobjects can be sliced. When taking a single column (dimension 0, e.g. [0, :]) or a single element, aQuantityis returned. Otherwise anAnalogSignal(actually a view) is returned, with the same metadata, except thatt_startis changed if the start index along dimension 1 is greater than 1. Note that slicing anAnalogSignalmay give a different result to slicing the underlying NumPy array since signals are always two-dimensional.- Operations available on this object:
== != + * /
- class neo.core.IrregularlySampledSignal(times, signal, units=None, time_units=None, dtype=None, copy=None, name=None, file_origin=None, description=None, array_annotations=None, **annotations)#
An array of one or more analog signals with samples taken at arbitrary time points.
A representation of one or more continuous, analog signals acquired at time
t_startwith a varying sampling interval. Each channel is sampled at the same time points.Inherits from
quantities.Quantity, which in turn inherits fromnumpy.ndarray.Parameters#
- times: quantity array 1D |numpy array 1D | list
The time of each data point. Must have the same size as signal.
- signal: quantity array 2D | numpy array 2D | list (data, channel)
The data itself organized as (n_data x n_channel)
- units: quantity units | None, default: None
The units for the signal if signal is numpy array or list Ignored if signal is a quantity array
- time_units: quantity units | None, default: None
The units for times if times is a numpy array or list Ignored if times is a quantity array
- dtype: numpy dtype | string | None, default: None
Overrides the signal array dtype Does not affect the dtype of the times which must be floats
- copy: bool | None, default: None
deprecated and no longer used (for NumPy 2.0 support). Will be removed.
- name: str | None, default: None
An optional label for the dataset
- description: str | None, default: None
An optional text description of the dataset
- file_origin: str | None, default: None
The filesystem path or url of the orginal data
- array_annotations: dict | None, default: None
Dict mapping strings to numpy arrays containing annotations for all data points
- annotations: dict
Optional additional metadata supplied by the user as a dict. Will be stored in the annotations attribute of the object
Notes#
- Attributes that can accessed for this object:
- sampling_intervals: quantity 1d array
Interval between each adjacent pair of samples (times[1:] - times[:-1])
- duration: quantity scalar
Signal duration, read-only (times[-1]-times[0])
- t_start: quantity scalar
Time when signal begins, read-only (times[0])
- t_stop: quantity scalar
Time when signal ends, read-only (times[-1])
- Slicing
- IrregularlySampledSignal objects can be sliced. When this
occurs, a new IrregularlySampledSignal (actually a view) is returned, with the same metadata, except that times is also sliced in the same way.
- Operations
==
!=
/
Examples#
>>> from neo.core import IrregularlySampledSignal >>> from quantities import s, nA >>> >>> irsig0 = IrregularlySampledSignal([0.0, 1.23, 6.78], [1, 2, 3], ... units='mV', time_units='ms') >>> irsig1 = IrregularlySampledSignal([0.01, 0.03, 0.12]*s, ... [[4, 5], [5, 4], [6, 3]]*nA) >>> irsig0 == irsig1 False
- class neo.core.ChannelView(obj, index, name=None, description=None, file_origin=None, array_annotations=None, **annotations)#
A tool for indexing a subset of the channels within an
AnalogSignalorIrregularlySampledSignal;Parameters#
- obj: Neo.AnalogSignal | Neo.IrregularlySampledSignal
The neo object to index
- index: list | np.ndarray
Boolean or integer mask to select the channels of interest
- name: str | None, default: None
A label for the dataset.
- description: str | None, default: None
Text description.
- file_origin: str | None, default: None
Filesystem path or URL of the original data file.
- array_annotations: dict | None, default: None
Dict mapping strings to numpy arrays containing annotations for all data points
- annotations: dict
Other use-specified metadata with keywords
- class neo.core.Event(times=None, labels=None, units=None, name=None, description=None, file_origin=None, array_annotations=None, **annotations)#
Array of events which are the start times of events along with the labels of the events
Parameters#
- times: quantity array 1d | list
The times of the events
- labels: numpy.ndarray 1d dtype=’U’ | list
Names or labels for the events
- units: quantity units | None, default: None
If times are list the units of the times If times is a quantity array this is ignored
- name: str | None, default: None
An optional label for the dataset
- description: str | None, default: None
An optional text descriptoin of the dataset
- file_orgin: str | None, default: None
The filesystem path or url of the original data file
- array_annotations: dict | None, default: None
Dict mapping strings to numpy arrays containing annotations for all data points
- **annotations: dict
Additional user specified metadata stored in the annotations attribue
Examples#
>>> from neo.core import Event >>> from quantities import s >>> import numpy as np >>> >>> evt = Event(np.arange(0, 30, 10)*s, ... labels=np.array(['trig0', 'trig1', 'trig2'], ... dtype='U')) >>> >>> evt.times array([ 0., 10., 20.]) * s >>> evt.labels array(['trig0', 'trig1', 'trig2'], dtype='<U5')
- class neo.core.Epoch(times=None, durations=None, labels=None, units=None, name=None, description=None, file_origin=None, array_annotations=None, **annotations)#
Array of epochs.
Parameters#
- times: quantity array 1D | numpy array 1D | list | None, default: None
The start times of each time period. If None, generates an empty array
- durations: quantity array 1D | numpy array 1D | list | quantity scalar | float | None, default: None
The length(s) of each time period. If a scalar/float, the same value is used for all time periods. If None, generates an empty array
- labels: numpy.array 1D dtype=’U’ | list | None, default: None
Names or labels for the time periods. If None, creates an empty array
- units: quantity units | str | None, default: None
The units for the time Required if the times is a list or NumPy, not required if it is a
Quantity
name: (str) A label for the dataset, description: (str) Text description, file_origin: (str) Filesystem path or URL of the original data file.
Usage:
>>> from neo.core import Epoch >>> from quantities import s, ms >>> import numpy as np >>> >>> epc = Epoch(times=np.arange(0, 30, 10)*s, ... durations=[10, 5, 7]*ms, ... labels=np.array(['btn0', 'btn1', 'btn2'], dtype='U')) >>> >>> epc.times array([ 0., 10., 20.]) * s >>> epc.durations array([ 10., 5., 7.]) * ms >>> epc.labels array(['btn0', 'btn1', 'btn2'], dtype='<U4')
Recommended attributes/properties:
- Optional attributes/properties:
- array_annotations:
(dict) Dict mapping strings to numpy arrays containing annotations for all data points
Note: Any other additional arguments are assumed to be user-specific metadata and stored in
annotations,
- class neo.core.SpikeTrain(times, t_stop, units=None, dtype=None, copy=None, sampling_rate=array(1.) * Hz, t_start=array(0.) * s, waveforms=None, left_sweep=None, name=None, file_origin=None, description=None, array_annotations=None, **annotations)#
SpikeTrainis aQuantityarray of spike times.It is an ensemble of action potentials (spikes) emitted by the same unit in a period of time.
Parameters#
- times: quantity array 1D | numpy array 1D | list
The times of each spike.
- t_stop: quantity scalar | numpy scalar |float
Time at which the SpikeTrain ended. This will be converted to the same units as times. This argument is required because it specifies the period of time over which spikes could have occurred. Note that
t_startis highly recommended for the same reason.- units: (quantity units) | None, default: None
Required if times is a list or numpy.ndarray` Not required if times is a quantities.Quantity
- dtype: numpy dtype | str | None, default: None
Due to change in copy behavior this argument is also deprecated during construction
- copy: bool, default: None
Deprecated in order to support NumPy 2.0 and will be removed.
- sampling_rate: quantity scalar, default: 1.0 pq.Hz
Number of samples per unit time for the waveforms.
- t_start: quantity scalar | numpy scalar | float
Time at which the`SpikeTrain` began. This will be converted to the same units as times.
- waveforms: quantity array 3D (n_spikes, n_channels, n_time) | None, default: None
- The waveforms of each spike if given must be of the correct shape
None indicates no waveforms
- left_sweep: (quantity array 1D) | None, default: None
Time from the beginning of the waveform to the trigger time of the spike.
- name: str | None, default: None
A label for the dataset.
- description: str | None, default: None
A text description of this dataset
- file_origin: str | Filesystem path | URL | None, default: None
The path or location of the original data file.
- array_annotations: dict
A dictonary mapping of strings to numpy arrays containing annotations for all data points
- annotations: dict
Other user defined metadata given as a dict
Notes#
Useful properties of a SpikeTrain
- sampling_period: quantity scalar
Interval between two samples (1/sampling_rate)
- duration: quantity scalar
Duration over which spikes can occur read-only (t_stop - t_start)
- spike_duration: quantity scalar
Duration of a waveform, read-only (waveform.shape[2] * sampling_period)
- right_sweep: quantity scalar
Time from the trigger times of the spikes to the end of the waveforms, read-only (left_sweep + spike_duration)
- times: quantity array 1D
Returns the
SpikeTrainas a quantity array.
- Slicing:
SpikeTrainobjects can be sliced. When this occurs, a newSpikeTrain(actually a view) is returned, with the same metadata, except thatwaveformsis also sliced in the same way (along dimension 0). Note that t_start and t_stop are not changed automatically, although you can still manually change them.
Examples#
>>> from neo.core import SpikeTrain >>> from quantities import s >>> >>> train = SpikeTrain([3, 4, 5]*s, t_stop=10.0) >>> train2 = train[1:3] >>> >>> train.t_start array(0.0) * s >>> train.t_stop array(10.0) * s >>> train <SpikeTrain(array([ 3., 4., 5.]) * s, [0.0 s, 10.0 s])> >>> train2 <SpikeTrain(array([ 4., 5.]) * s, [0.0 s, 10.0 s])>
- class neo.core.ImageSequence(image_data, units=Dimensionless('dimensionless', 1.0 * dimensionless), dtype=None, copy=None, t_start=array(0.) * s, spatial_scale=None, frame_duration=None, sampling_rate=None, name=None, description=None, file_origin=None, **annotations)#
Representation of a sequence of images, as an array of three dimensions organized as [frame][row][column].
Inherits from
quantities.Quantity, which in turn inherits fromnumpy.ndarray.usage:
>>> from neo.core import ImageSequence >>> import quantities as pq >>> >>> img_sequence_array = [[[column for column in range(20)]for row in range(20)] ... for frame in range(10)] >>> image_sequence = ImageSequence(img_sequence_array, units='V', ... sampling_rate=1 * pq.Hz, ... spatial_scale=1 * pq.micrometer) >>> image_sequence ImageSequence 10 frames with width 20 px and height 20 px; units V; datatype int64 sampling rate: 1.0 spatial_scale: 1.0 >>> image_sequence.spatial_scale array(1.) * um
- Required attributes/properties:
- image_data:
(3D NumPy array, or a list of 2D arrays) The data itself
- units:
(quantity units)
- sampling_rate:
or frame_duration (quantity scalar) Number of samples per unit time or duration of a single image frame. If both are specified, they are checked for consistency.
- spatial_scale:
(quantity scalar) size for a pixel.
- t_start:
(quantity scalar) Time when sequence begins. Default 0.
- Recommended attributes/properties:
- name:
(str) A label for the dataset.
- description:
(str) Text description.
- file_origin:
(str) Filesystem path or URL of the original data file.
- Optional attributes/properties:
- dtype:
(numpy dtype or str) Override the dtype of the signal array.
- copy:
deprecated
Note: Any other additional arguments are assumed to be user-specific metadata and stored in
annotations.- Properties available on this object:
- sampling_rate:
(quantity scalar) Number of samples per unit time. (1/
frame_duration)- frame_duration:
(quantity scalar) Duration of each image frame. (1/
sampling_rate)- spatial_scale:
Size of a pixel
- duration:
(Quantity) Sequence duration, read-only. (size *
frame_duration)- t_stop:
(quantity scalar) Time when sequence ends, read-only. (
t_start+duration)
- class neo.core.RectangularRegionOfInterest(image_sequence, x, y, width, height, name=None, description=None, file_origin=None, **annotations)#
Representation of a rectangular ROI
Usage:
>>> roi = RectangularRegionOfInterest(20.0, 20.0, width=5.0, height=5.0) >>> signal = image_sequence.signal_from_region(roi)
- Required attributes/properties:
- x, y:
(integers or floats) Pixel coordinates of the centre of the ROI
- width:
(integer or float) Width (x-direction) of the ROI in pixels
- height:
(integer or float) Height (y-direction) of the ROI in pixels
- class neo.core.CircularRegionOfInterest(image_sequence, x, y, radius, name=None, description=None, file_origin=None, **annotations)#
Representation of a circular ROI
Usage:
>>> roi = CircularRegionOfInterest(20.0, 20.0, radius=5.0) >>> signal = image_sequence.signal_from_region(roi)
- Required attributes/properties:
- x, y:
(integers or floats) Pixel coordinates of the centre of the ROI
- radius:
(integer or float) Radius of the ROI in pixels
- class neo.core.PolygonRegionOfInterest(image_sequence, *vertices, name=None, description=None, file_origin=None, **annotations)#
Representation of a polygonal ROI
Usage:
>>> roi = PolygonRegionOfInterest( ... (20.0, 20.0), ... (30.0, 20.0), ... (25.0, 25.0) ... ) >>> signal = image_sequence.signal_from_region(roi)
- Required attributes/properties:
- vertices:
tuples containing the (x, y) coordinates, as integers or floats, of the vertices of the polygon