
Neo core¶
This figure shows the main data types in Neo:
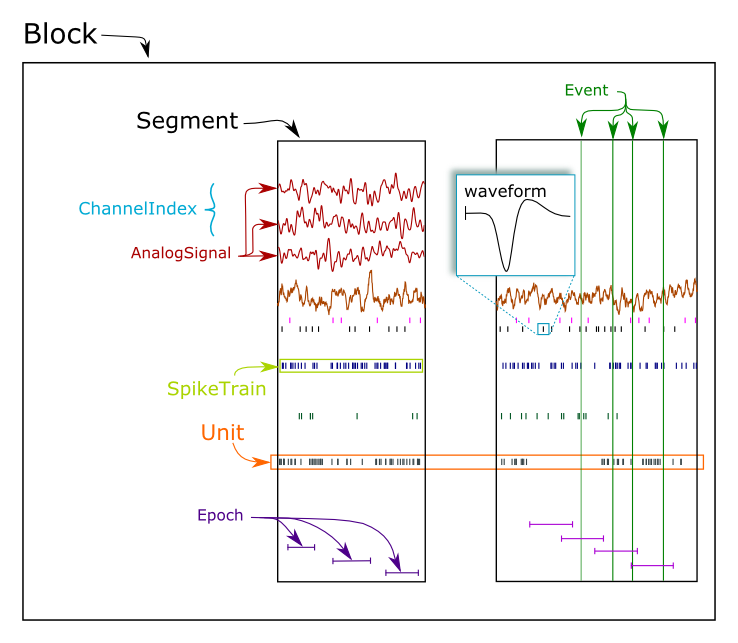
Neo objects fall into three categories: data objects, container objects and grouping objects.
Data objects¶
These objects directly represent data as arrays of numerical values with associated metadata (units, sampling frequency, etc.).
AnalogSignal: A regular sampling of a single- or multi-channel continuous analog signal.IrregularlySampledSignal: A non-regular sampling of a single- or multi-channel continuous analog signal.SpikeTrain: A set of action potentials (spikes) emitted by the same unit in a period of time (with optional waveforms).Event: An array of time points representing one or more events in the data.Epoch: An array of time intervals representing one or more periods of time in the data.
Container objects¶
There is a simple hierarchy of containers:
Segment: A container for heterogeneous discrete or continous data sharing a common clock (time basis) but not necessarily the same sampling rate, start time or end time. ASegmentcan be considered as equivalent to a “trial”, “episode”, “run”, “recording”, etc., depending on the experimental context. May contain any of the data objects.Block: The top-level container gathering all of the data, discrete and continuous, for a given recording session. ContainsSegment,UnitandChannelIndexobjects.
Grouping objects¶
These objects express the relationships between data items, such as which signals were recorded on which electrodes, which spike trains were obtained from which membrane potential signals, etc. They contain references to data objects that cut across the simple container hierarchy.
ChannelIndex: A set of indices intoAnalogSignalobjects, representing logical and/or physical recording channels. This has two uses:
- for linking
AnalogSignalobjects recorded from the same (multi)electrode across severalSegments.- for spike sorting of extracellular signals, where spikes may be recorded on more than one recording channel, and the
ChannelIndexcan be used to associate eachUnitwith the group of recording channels from which it was obtained.
Unit: links theSpikeTrainobjects within aBlock, possibly across multiple Segments, that were emitted by the same cell. AUnitis linked to theChannelIndexobject from which the spikes were detected.
NumPy compatibility¶
Neo data objects inherit from Quantity, which in turn inherits from NumPy
ndarray. This means that a Neo AnalogSignal is also a Quantity
and an array, giving you access to all of the methods available for those objects.
For example, you can pass a SpikeTrain directly to the numpy.histogram()
function, or an AnalogSignal directly to the numpy.std() function.
If you want to get a numpy.ndarray you use magnitude and rescale from quantities:
>>> np_sig = neo_analogsignal.rescale('mV').magnitude
>>> np_times = neo_analogsignal.times.rescale('s').magnitude
Relationships between objects¶
Container objects like Block or Segment are gateways to
access other objects. For example, a Block can access a Segment
with:
>>> bl = Block()
>>> bl.segments
# gives a list of segments
A Segment can access the AnalogSignal objects that it contains with:
>>> seg = Segment()
>>> seg.analogsignals
# gives a list of AnalogSignals
In the Neo diagram below, these one to many relationships are represented by cyan arrows. In general, an object can access its children with an attribute childname+s in lower case, e.g.
Block.segmentsSegments.analogsignalsSegments.spiketrainsBlock.channel_indexes
These relationships are bi-directional, i.e. a child object can access its parent:
Segment.blockAnalogSignal.segmentSpikeTrain.segmentChannelIndex.block
Here is an example showing these relationships in use:
from neo.io import AxonIO
import urllib
url = "https://portal.g-node.org/neo/axon/File_axon_3.abf"
filename = './test.abf'
urllib.urlretrieve(url, filename)
r = AxonIO(filename=filename)
bl = r.read() # read the entire file > a Block
print(bl)
print(bl.segments) # child access
for seg in bl.segments:
print(seg)
print(seg.block) # parent access
In some cases, a one-to-many relationship is sufficient. Here is a simple example with tetrodes, in which each tetrode has its own group.:
from neo import Block, ChannelIndex
bl = Block()
# the four tetrodes
for i in range(4):
chx = ChannelIndex(name='Tetrode %d' % i,
index=[0, 1, 2, 3])
bl.channelindexes.append(chx)
# now we load the data and associate it with the created channels
# ...
Now consider a more complex example: a 1x4 silicon probe, with a neuron on channels 0,1,2 and another neuron on channels 1,2,3. We create a group for each neuron to hold the Unit object associated with this spike sorting group. Each group also contains the channels on which that neuron spiked. The relationship is many-to-many because channels 1 and 2 occur in multiple groups.:
bl = Block(name='probe data')
# one group for each neuron
chx0 = ChannelIndex(name='Group 0',
index=[0, 1, 2])
bl.channelindexes.append(chx0)
chx1 = ChannelIndex(name='Group 1',
index=[1, 2, 3])
bl.channelindexes.append(chx1)
# now we add the spiketrain from Unit 0 to chx0
# and add the spiketrain from Unit 1 to chx1
# ...
Note that because neurons are sorted from groups of channels in this situation, it is natural that the ChannelIndex contains a reference to the Unit object.
That unit then contains references to its spiketrains. Also note that recording channels can be
identified by names/labels as well as, or instead of, integer indices.
See Typical use cases for more examples of how the different objects may be used.
Neo diagram¶
- Object:
- With a star = inherits from
Quantity
- With a star = inherits from
- Attributes:
- In red = required
- In white = recommended
- Relationship:
- In cyan = one to many
- In yellow = properties (deduced from other relationships)
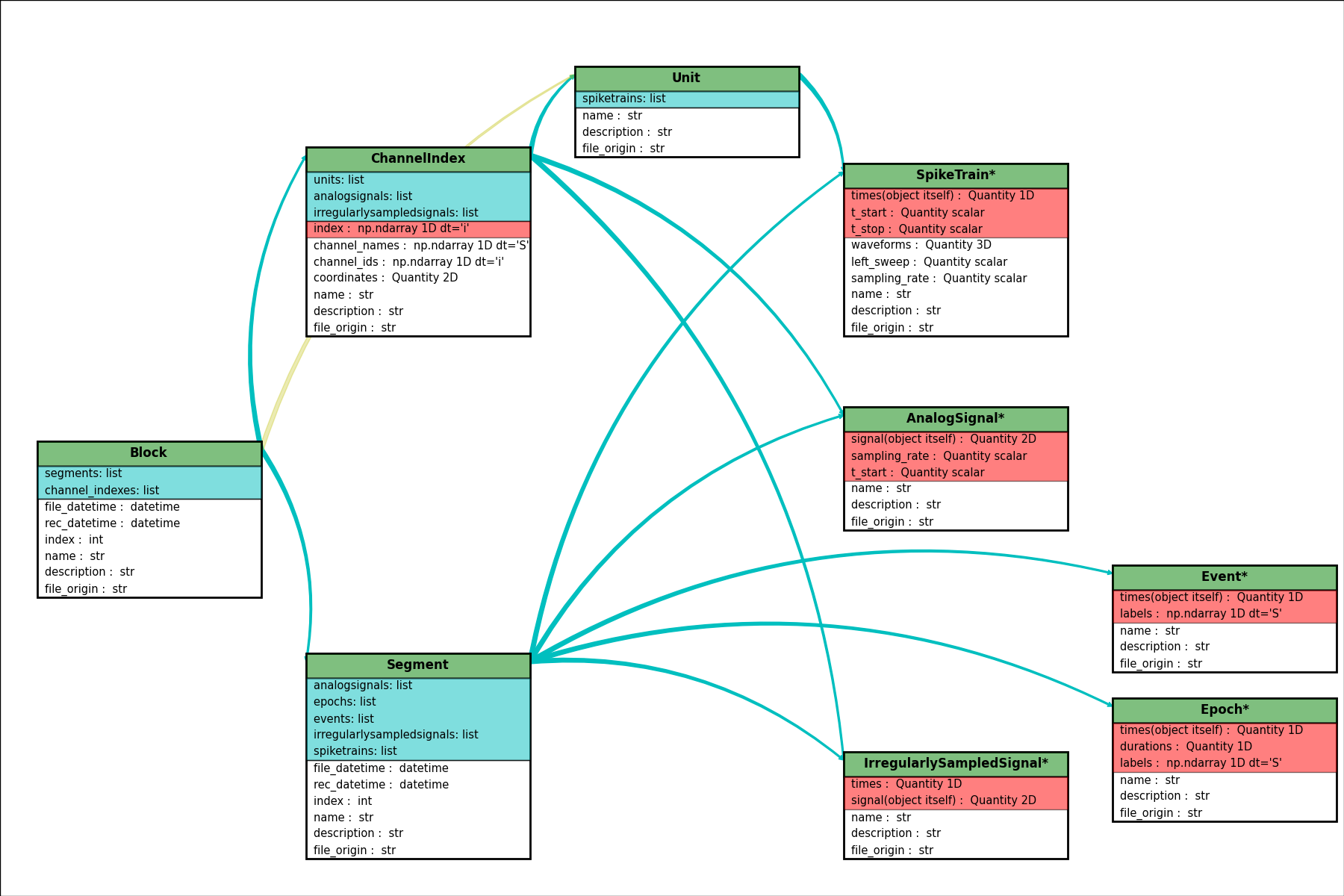
Click here for a better quality SVG diagram
{kind=link}
For more details, see the API Reference.
Initialization¶
Neo objects are initialized with “required”, “recommended”, and “additional” arguments.
- Required arguments MUST be provided at the time of initialization. They are used in the construction of the object.
- Recommended arguments may be provided at the time of initialization. They are accessible as Python attributes. They can also be set or modified after initialization.
- Additional arguments are defined by the user and are not part of the Neo object model. A primary goal of the Neo project is extensibility. These additional arguments are entries in an attribute of the object: a Python dict called
annotations. Note : Neo annotations are not the same as the __annotations__ attribute introduced in Python 3.6.
Example: SpikeTrain¶
SpikeTrain is a Quantity, which is a NumPy array containing values with physical dimensions. The spike times are a required attribute, because the dimensionality of the spike times determines the way in which the Quantity is constructed.
Here is how you initialize a SpikeTrain with required arguments:
>>> import neo
>>> st = neo.SpikeTrain([3, 4, 5], units='sec', t_stop=10.0)
>>> print(st)
[ 3. 4. 5.] s
You will see the spike times printed in a nice format including the units.
Because st “is a” Quantity array with units of seconds, it absolutely must have this information at the time of initialization. You can specify the spike times with a keyword argument too:
>>> st = neo.SpikeTrain(times=[3, 4, 5], units='sec', t_stop=10.0)
The spike times could also be in a NumPy array.
If it is not specified, t_start is assumed to be zero, but another value can easily be specified:
>>> st = neo.SpikeTrain(times=[3, 4, 5], units='sec', t_start=1.0, t_stop=10.0)
>>> st.t_start
array(1.0) * s
Recommended attributes must be specified as keyword arguments, not positional arguments.
Finally, let’s consider “additional arguments”. These are the ones you define for your experiment:
>>> st = neo.SpikeTrain(times=[3, 4, 5], units='sec', t_stop=10.0, rat_name='Fred')
>>> print(st.annotations)
{'rat_name': 'Fred'}
Because rat_name is not part of the Neo object model, it is placed in the dict annotations. This dict can be modified as necessary by your code.
Annotations¶
As well as adding annotations as “additional” arguments when an object is
constructed, objects may be annotated using the annotate() method
possessed by all Neo core objects, e.g.:
>>> seg = Segment()
>>> seg.annotate(stimulus="step pulse", amplitude=10*nA)
>>> print(seg.annotations)
{'amplitude': array(10.0) * nA, 'stimulus': 'step pulse'}
Since annotations may be written to a file or database, there are some
limitations on the data types of annotations: they must be “simple” types or
containers (lists, dicts, tuples, NumPy arrays) of simple types, where the simple types
are integer, float, complex, Quantity, string, date, time and
datetime.
Array Annotations¶
Next to “regular” annotations there is also a way to annotate arrays of values
in order to create annotations with one value per data point. Using this feature,
called Array Annotations, the consistency of those annotations with the actual data
is ensured.
Apart from adding those on object construction, Array Annotations can also be added
using the array_annotate() method provided by all Neo data objects, e.g.:
>>> sptr = SpikeTrain(times=[1, 2, 3]*pq.s, t_stop=3*pq.s)
>>> sptr.array_annotate(index=[0, 1, 2], relevant=[True, False, True])
>>> print(sptr.array_annotations)
{'index': array([0, 1, 2]), 'relevant': array([ True, False, True])}
Since Array Annotations may be written to a file or database, there are some limitations on the data types of arrays: they must be 1-dimensional (i.e. not nested) and contain the same types as annotations:
integer,float,complex,Quantity,string,date,timeanddatetime.